Mila urte igaro dira Donemiliagan abade batek hainbat glosa idatzi zituenetik, latinez idazten ari zen testua azaltzeko helburuarekin. Jçioq dugu idatzi zuen orrialde batean. Guec ajutu eç dugu beste batean. Hizkuntza erromantze batean (gaztelania edo aragoiera den eztabaidan dago) eta euskaraz idatzi zituen ohar horiek. Euskarazko testu ziurrik zaharrena da, eta ez dakigu egilea nafarra, arabarra edo errioxarra ote zen.
Mila urte igaro dira eta euskarak aldaketa asko izan ditu geroztik. Egunotan 50 urte beteko dira Arantzazun Euskara Batua sortuko zuen Batzarra egin zenetik. Hiztegiak sortu ditugu. Entziklopediak eratu ditugu. Euskarazko zientzia eta teknologia tresnak ditugu. Euskarazko irratiak eta telebistak sortu dira. Euskara Ilargira iristeko prest dago ere.
Wikipedia munduko Entziklopediarik handiena da, eta euskarazko webgunerik bisitatuena. Wikipediak badu senide bat, sei urte bete dituen Wikidata. Bertan, orain arte, kontzeptuak gehitzeko aukera zegoen. Ez da lan makala egindakoa, sei urte hauetan 48.000.000 kontzeptu baino gehiago sortu dira datu-base erraldoi horretan, eta euskarazko Wikipedian horien erabilpen masiboa egiten dugu. Orain arte, baina, kontzeptuak igo ditugu eta ez hitzak, esamoldeak edo hitzen formak.
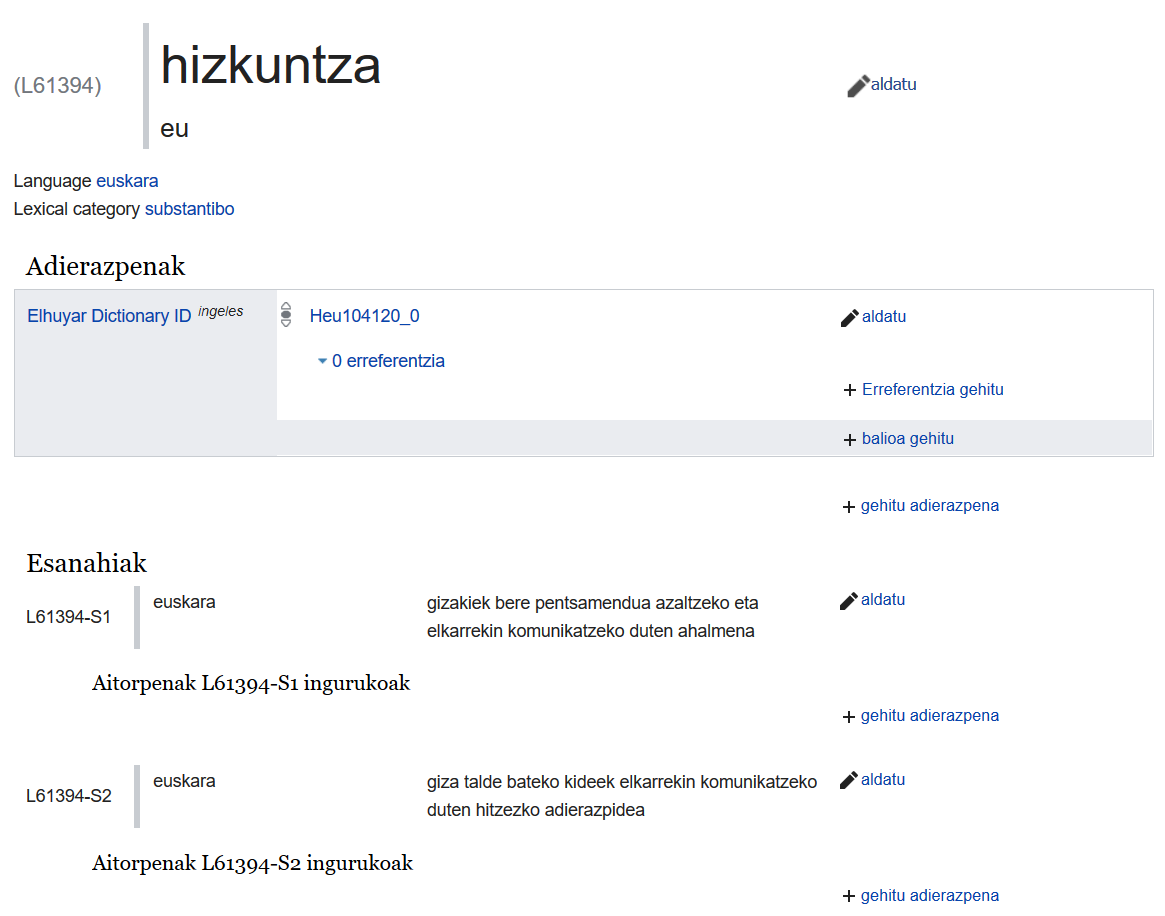
2013an bertan sortu zen lehenengo eztabaida: kontzeptuak definitzeko gai baginen, hitzak ere lexikografikoki definitzeko aukera izan beharko genuke. Baina ez zen hain erraza, eta 5 urteko eztabaida izan da gaiaren inguruan. 2016an lehen garapen plana egin zen, bi urtez softwarea prestatzeko erronkarekin. Eta eztabaidak jarraitu du: nola heldu behar zaio hizkuntza guztietako hitz guztiak bildu, antolatu eta lotzeko erronkari? Gaur, 2018ko maiatzaren 23an, lehenengo hitzak igo dira Wikidatara, eta dagoeneko komunitatea hasi da gehiago gehitzen.
Orain urtebete eskaera bat egin ziguten: posible al da euskarazko “Easter Egg” bat sortzea? Hauek txisteak izaten dira, letrak eta hitzak batzeko balio dutenak. Badira batzuk bertan. Adibidez L314 (L letrak “lexema” esan nahi du) katalanezko pi hitza da. L42 ingelesezko answer da (txistea ulertzeko pista Q42 itemean dago). L24601 frantsesezko condamné hitza da (galdetu Jean Valjeani). Euskaraz ere lehen hitza aukeratu eta Easter Egg gisako sorpresatxo bat prestatzea zen helburua. Eta zein hitz hobea izioki baino? Euskarazko lehen hitz idatzi izan bazen, hemen ere hala izan beharko litzateke, ezta? Baina sorpresaren gakoa hitzari zenbaki bat lotzea zen. LEET hizkera erabili dugu horretarako. Hizkera hau 1980ko hamarkadan garatu zen, Interneten hasieran, eta zenbakiak eta letrak nahastearen ondorioa zen. Horrela e letra 3gatik alda zit3k33n, edo a letra 4 b4t3ng4t1k. Izioki hitzan erraza zen 1710k1 idaztea, baina k hori ere ordezkatu behar zenez, 8 jartzea pentsatu genuen. L171081 da lehen lexema, euskaraz igotako lehen kodea, lehen hitz haren baliokidea.
Eta orain zer?
Oraindik probetan gaude. Beste hitz batzuk igo daitezke, adibidez, abade. Baina hizkuntza guztietako hitz guztietako forma guztiak igotzeak baditu bere arazoak. Adibidez, esan dezakegu zein den hitz baten forma singular eta plurala, baina softwarea oraindik ez dago prest mugagabea adierazteko. Laster forma (F letrarekin adieraziko dira) guztiak (deklinazioak, adibidez) automatikoki sortzeko aukera egongo da, baita bilaketak egin eta hizkuntzen arteko loturak jartzeko.
Formez gain, zentzuak ere adierazteko aukera egongo da (S letrarekin adieraziko dira). Eta erabilera adibideak jartzeko aukera. Itzulpen automatikoak egiten dituzten sistemek aukera bat izango dute hitzen baliokideak bilatzeko, eta hitzen esanahiak ulertzeko.
Eta laster ere etimologiak zehazteko aukera egongo da, gaur egun Wiktionaryn dagoen bezala. Gaur egun Etytree deitzen den tresnak dituen aukerak masiboki erabili ahal izango ditugu. Eta batek daki zer beste aukera izango ditugun etorkizunean. Hau hasi besterik ez da egin… garai interesgarriak bizi ditugu!










{kind=link}