Letra-zopak eta Scrabble: zein da euskarazko letrarik ohikoena?

Egunean Behin aplikazio arrakastatsuan letra-zopak sartu dituzte berrikuntza gisa. Galderetako asko, orain arte, Wikipediatik (zein Wikidatako query zerbitzutik) sortu dira, baina hau zerbait berria da. Sustatun argitaratutako mezu honetan letra-zopen atzeko teknologia zein den azaltzen dute, eta atal berezia eskaintzen diote ausazko letren sarrerari.
“Euskararen hizki-maiztasunerako Ahotsak taldeak egindako azterketa hau erabili dugu” esaten dute mezuan, eta duda bat planteatzen dute: izan ere corpus hori ez dago hiztegian dauden hitzetan oinarrituta. Beraz, baliteke A eta E berez dagokiona baino gehiagotan agertzea eta N, T eta R behar baino gutxiago.
Wikidatan lexemekin lanean hasi ginen orain hilabete batzuk, eta euskara da laugarren hizkuntza hitz kopuruan (lehenengoa esanahi kopuruari dagokionez). Ez dugu hiztegi osoa sartuta (oraindik) baina baditugu 10.000 sustantiborik ohikoenak, Elhuyarren ikasleen hiztegitik hartuak eta Corsyntax datubaseko aditz ia guztiak igota. Hitz bakoitzaren formak sar daitezke bilaketan (abade, abadearen, abadearengatik…), baita aditzenak ere (sartu, sar, sartzen, sartuko…). Bilaketa egin dezakegu, beraz, hiztegian agertzen diren hitzekin (14.359 ditugu) zein erabili daitezkeen hitz guztiekin (686.448 ditugu). Ahotsakek egindako azterketan ez bezala, hau ez da erabilera corpus bat, baizik eta hitzen corpus bat.
Letrarik ohikoena
Orain arte egindako bilaketa guztietan, lehen letrarik ohikoena zein zen jakin genezake (bilaketa honetan forma guztiak agertzen dira, ez hiztegiko hitzak bakarrik):
Hala ere, WikidataFacts kontuari galdera eginda, bilaketa hori aldatu dugu eta aukera dugu orain edozein posizioren arabera letren maiztasuna ezagutzeko (hiztegiko hitzetan bakarrik):
Jakina denez, euskaraz ez da ohikoa hitzak R letrarekin hastea, baina bada oso ohikoa barruan agertzea. Bestetik, aditz kopuru handia igota dugu bestelako hitzekin alderatuta, eta horrek ere izan dezake eraginik letren frekuentzian. Euskarazko aditzen kopururik handiena “tu” letrekin amaitzen da, eta beste talde handi bat “du” letrekin. Hiztegiko forma bakarrik hartzen badugu, “t” eta “u” letren maiztasuna igoko da, nahiz eta gero hitz egiterakoan horiek gutxiago diren: “sartu” aditzaren formen artean “sar”, “sartzea” edo “sartzen” agertuko dira maiz, eta “u” letra ez da hortik ageri.
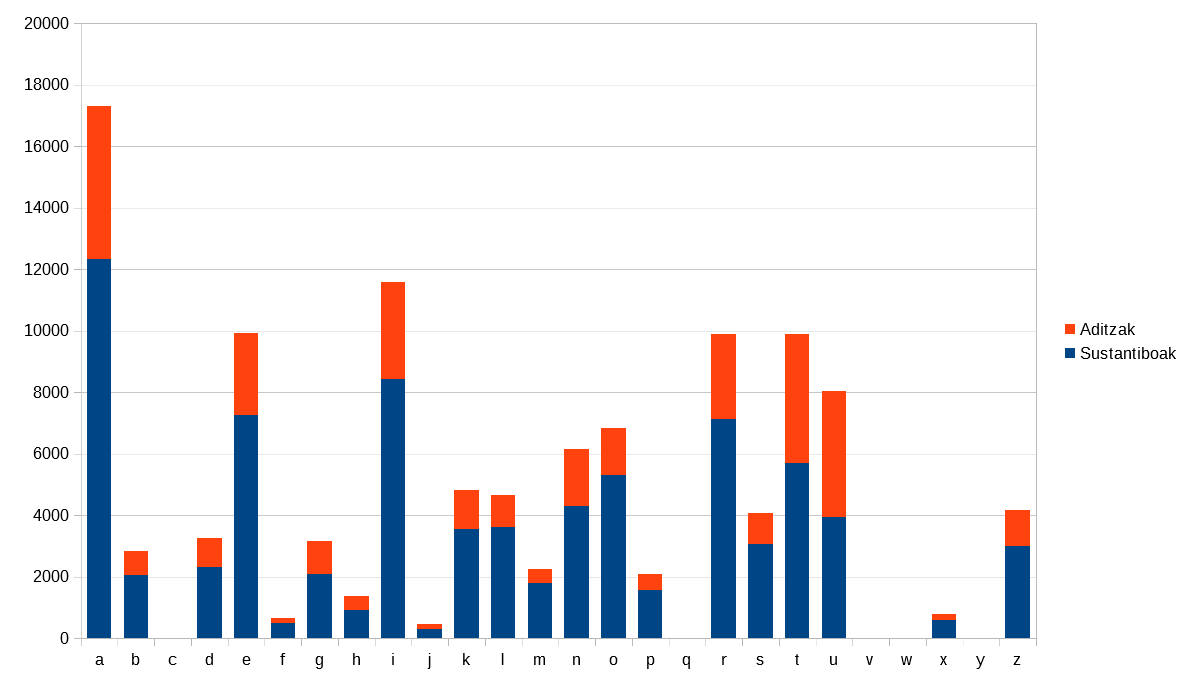
Grafikan ikusten den bezala, a eta i letrak dira euskaraz ohikoenak, eta e, r eta t datoz ondoren. O letra ohikoagoa da substantiboetan, baina u letrak irabazten du aditzak sartzen ditugunean. T kontsonante ohikoa da, baina askoz ohikoago bilakatzen da aditzak sartzerakoan. Bitxia bada ere, tx, tz eta ts soinuak sortzen dituzten kontsonanteen artean, x da ez-ohikoena, z eta s askoz arruntagoak izanik.
Adjektiboak eta substantiboak faltan
Noski, adibide honetan aditzen ordezkaritza hiztegi batean baino handiagoa da. Adjektiborik ia ez dugu, eta oraindik ere beste hamarnaka mila substantibo falta dira. Hiztegi osoa aintzat hartuta, pentsa daiteke t eta u ez direla hain ohikoak izango.
Bestetik, aditz bakoitzarekin bost forma igo dira Wikidatara (Sartu, sar, sartuko, sartzea, sartzen) baina izen bakoitzaren 65 forma igo dira (ez ditut guztiak zerrendatuko). Beraz, forma kopuru osoa kontuan hartzen badugu, desoreka are eta handiagoa izango da etorkizunean.
Demagun aditz kopurua ez dela hazten (dagoeneko zerrenda horretan zeudenak sartu ditugulako) baina adjektibo eta izen kopurua laukoizten dela. Hau izango litzateke emaitza:

Proiekzio honen arabera, u ez litzateke hain ohikoa izango, baina ematen digu pista on bat hiztegiko distribuzio posible baten inguruan. Ehunekotan, honela:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| %15,35 | %2,53 | %0,02 | %2,88 | %8,97 | %0,60 | %2,67 | %1,16 | %10,43 | %0,39 | %4,37 | %4,40 | %2,14 | %5,39 | %6,44 | %1,93 | %0,00 | %8,86 | %3,74 | %7,62 | %5,62 | %0,01 | %0,01 | %0,72 | %0,01 | %3,73 |
Scrabble
Orain urte batzuk arrakasta izan zuen Apalabrados izeneko aplikazioak. Srabble jokoaren bertsio bat zen, eta euskaraz jokatzeko aukera ematen zuen. Ez dut gogoan nola zen puntuazioa, baina goikoa ikusita, egin daiteke proposamen bat. Badago banaketa ez ofizial bat, Euskarbel izenekoa, eta ingelesezko Wikipediak banaketa bat ematen digu:

Scrabble jokoak 100 fitxa ditu, eta beste bi zuri. Ingelesezko banaketa eginda, eta letra bikoitzik baimendu gabe, honakoa izango litzateke banaketa hobea euskaraz:
